 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttaching Multiple Prepositional Phrases: Generalized Backed-off Estimation
Oct 16, 1997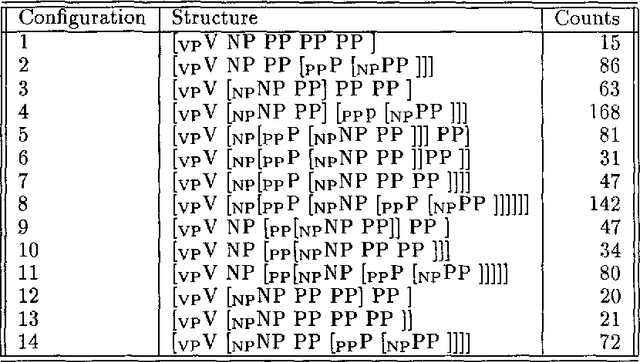
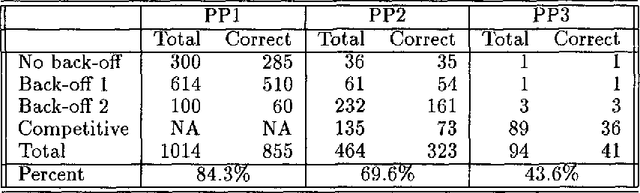
There has recently been considerable interest in the use of lexically-based statistical techniques to resolve prepositional phrase attachments. To our knowledge, however, these investigations have only considered the problem of attaching the first PP, i.e., in a [V NP PP] configuration. In this paper, we consider one technique which has been successfully applied to this problem, backed-off estimation, and demonstrate how it can be extended to deal with the problem of multiple PP attachment. The multiple PP attachment introduces two related problems: sparser data (since multiple PPs are naturally rarer), and greater syntactic ambiguity (more attachment configurations which must be distinguished). We present and algorithm which solves this problem through re-use of the relatively rich data obtained from first PP training, in resolving subsequent PP attachments.
Parsing with Principles and Probabilities
Aug 02, 1994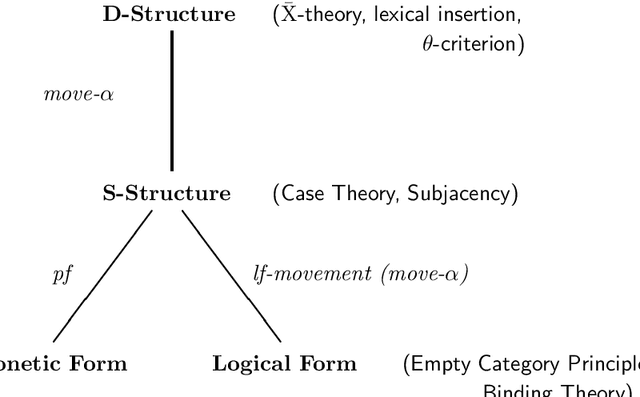
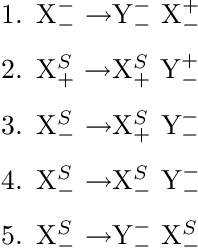
This paper is an attempt to bring together two approaches to language analysis. The possible use of probabilistic information in principle-based grammars and parsers is considered, including discussion on some theoretical and computational problems that arise. Finally a partial implementation of these ideas is presented, along with some preliminary results from testing on a small set of sentences.